hadoop replication Replication factor is the main HDFS fault tolerance feature. Arenadata Docs Guide describes how to change the replication factor and how HDFS works with different replication rates 20-30 quick leveling routine (7 hours) (20% xp pot) *Not Required but helps. 1. collect heroic sagas at 20 (Feywild, Ravenloft, Gianthold, Sharn, Cogs) 2. King's Forest slayers (Grim Disturbance) Video: How to Find Grim Disturbance. farm the swamp for GD - have at least 4 members in group for max spawns. 7500 slayers in 1 hour (200% slayer .
0 · namespace in hadoop
1 · hdfs full form in hadoop
2 · hadoop hdfs file replication factor
3 · hadoop hdfs data replication
4 · hadoop 2 hdfs replication factor
5 · explain hdfs architecture with diagram
6 · default block size in hadoop
7 · datanode and namenode in hadoop
16GB RAM for Dell PowerEdge R320, R420, R420xr, R520, R620, R720, R720xd, R820, R920 | 12th Gen. Rack Servers | DDR3 1600MHz ECC RDIMM PC3-12800 2Rx4 1.5V Registered DIMM Server Memory Module. $ 13.99. Free Shipping. Direct from A-Tech. A-Tech StoreVisit Store.
The Replication Factor is nothing but it is a process of making replicate or duplicate’s of data so let’s discuss them one by one with the . HDFS Replication. The Apache Hadoop system is designed to store and manage large sets of data including HDFS and Hive data sets reliably. DLM 1.1 supports both HDFS . Optimizing replica placement distinguishes HDFS from most other distributed file systems. This is a feature that needs lots of tuning and experience. The purpose of a rack-aware replica placement policy is to improve data .
chanel 19 tasche gro?
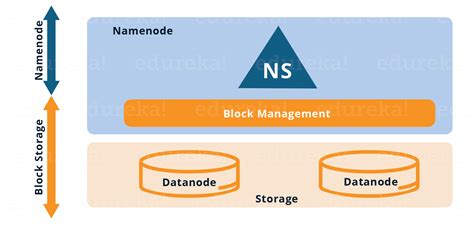
Hadoop Distributed File System (HDFS) is the storage component of Hadoop. All data stored on Hadoop is stored in a distributed .Replication factor is the main HDFS fault tolerance feature. Arenadata Docs Guide describes how to change the replication factor and how HDFS works with different replication ratesHDFS stores each file as a sequence of blocks. The blocks of a file are replicated for fault tolerance. The NameNode makes all decisions regarding replication of blocks. It periodically . REPLICA PLACEMENT: A simple but non-optimal policy is to place replicas on unique racks. This approach is quite robust because in an event of failure of a whole rack the data is preserved in the.
Hadoop distributed file system (HDFS) is designed to reliably store very large files across machines in a large cluster. It stores each file as a sequence of blocks; all blocks in a file except.
This command recursively changes the replication factor of all files under the root directory /. Syntax: hdfs dfs -setrep [-R] [-w] where -w flag requests . Changing the replication factor doesn't change the replication factor of existing files but only the new files that will be created after issuing the "hdfs dfs -setrep" command You will have to manually change the replication factor of the old files. To bulk change the replication factor $ hdfs dfs -setrep -R -w 2 /apps/Replication factor can’t be set for any specific node in cluster, you can set it for entire cluster/directory/file. dfs.replication can be updated in running cluster in hdfs-sie.xml.. Set the replication factor for a file- hadoop dfs -setrep -w file-path Or set it recursively for directory or for entire cluster- hadoop fs -setrep -R -w 1 /
hadoop fs -D dfs.replication=5 -copyFromLocal file.txt /user/xxxx When a NameNode restarts, it makes sure under-replicated blocks are replicated. Hence the replication info for the file is stored (possibly in nameNode ).You can also use CDP Private Cloud Base Replication Manager to replicate HDFS data to and from cloud, however you cannot replicate data from one cloud instance to another using Replication Manager. . This is in line with rsync/Hadoop DistCp behavior. Alerts: Choose to generate alerts for various state changes in the replication workflow. .Block Replication. Before discussing what makes HDFS fault-tolerant and highly available, let’s first understand the term fault tolerance. Wikipedia defines fault tolerance as the property that enables a system to continue operating properly in the event of the failure of some of its components. . In practice, Hadoop places the first . I am new to Hadoop and I want to understand how do we determine the highest replication factor we can have for any given cluster. I know that the default setting is 3 replicas, but if I have a cluster with 5 node what is the highest .
Replication factor is the main HDFS fault tolerance feature. Arenadata Docs Guide describes how to change the replication factor and how HDFS works with different replication rates . Hadoop Command-line User commands. Administration commands. Debug commands. HDFS CLI classpath. dfs. envvars. fetchdt. fsck. getconf. groups. httpfs .
The existing implementation of HDFS in Hadoop performs replication in a pipelined manner which takes much time for replication. Here proposed system is an alternative parallel approach for . WHAT IS DATA REPLICATION IN HDFS: As we saw in the HDFS architecture that each file is first broken down into blocks of 128MB (default) and then three (default) replicas of each block is created . The rate of replication work is throttled by HDFS to not interfere with cluster traffic when failures happen during regular cluster load. The properties that control this are dfs.namenode.replication.work.multiplier.per.iteration (2), dfs.namenode.replication.max-streams (2) and dfs.namenode.replication.max-streams-hard-limit (4).The foremost .
According to the Hadoop : Definitive Guide. Hadoop’s default strategy is to place the first replica on the same node as the client (for clients running outside the cluster, a node is chosen at random, although the system tries not to pick nodes that are too full or too busy).
4.Replication is done by data nodes, and master is informed. 5.Metadata is created on Name node about number of blocks, location of data nodes where blocks are placed and their replication.}. 3.3 Modified Data Replication Process of Hadoop. To provide fault tolerant nature Hadoop replicates every block of file. By default three replicas are formed. The Hadoop Distributed File System (HDFS) is the storage of choice when it comes to large-scale distributed systems. In addition to being efficient and scalable, HDFS provides high throughput and .
The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware. It has many similarities with existing distributed file systems. . Replication of data blocks does not occur when the NameNode is in the Safemode state. The NameNode receives Heartbeat and Blockreport messages from the DataNodes. A . Data replication is the primary fault tolerance mechanism and the core of the HDFS storage model. It consists of creating redundant copies of the data blocks so that, in the event of a failure, there are still replicas available in the system [].The replicated data are stored in different nodes of the cluster in such a way that the blocks can be accessed from any DN that . As we all know Hadoop is mainly configured for storing the large size data which is in petabyte, this is what makes Hadoop file system different from other file systems as it can be scaled, nowadays file blocks of 128MB to 256MB are considered in Hadoop. Replication In HDFS Replication ensures the availability of the data. Replication is making . Here is the documentation that explains block placement policy. Currently, HDFS replication is 3 by default which means there are 3 replicas of a block. The way they are placed is: One block is placed on a datanode on a unique rack.
The Hadoop Distributed File System (HDFS) is a key component of the Apache Hadoop ecosystem, designed to store and manage large volumes of data across multiple machines in a distributed manner. It provides high-throughput access to data, making it suitable for applications that deal with large datasets, such as big data analytics, machine learning, and . Hadoop replication factor precedence. 1. Changing replication factor in hadoop. 3. HDFS single node replication. 0. HDFS replication factor on single node cluster. Hot Network Questions Lexicographically earliest permutation of the initial segment of nonnegative integers subject to divisibility constraints
chanel muski
namespace in hadoop
is louis vuitton cheaper in london
hdfs full form in hadoop
hadoop hdfs file replication factor
Published May 16, 2024 at 8:14 AM PDT. Associated Press. The LDS temple in Salt Lake City, Utah. City officials have approved a proposal from the Church of Jesus Christ of Latter-day Saints to .
hadoop replication|hdfs full form in hadoop